차원 축소(Dimensionality)
특성 선택(feature selection)
원본 특성에서 일부를 선택한다.
특성 추출(feature extraction)
일련의 특성에서 얻은 정보로 새로운 특성을 만든다.
순차 특성 선택(sequential feature selection)
탐욕적 탐색 알고리즘(greedy search algorithm)으로 초기 d 차원의 특성 공간을 k<d인 k차원의 특성 부분
공간으로 축소한다.
특성 선택 알고리즘은 주어진 문제에서 가장 관련이 높은 특성 부분 집합을 자동으로 선택하는 것이 목적이다.
관련없는 특성이나 잡음을 제거하고, 계산 효율성을 높이는 것이 목적
(관련 없는 특성이나 잡음을 제거하여 계싼 효율성을 높이고 모델의 일반화 오차를 줄인다.)
-> 규제를 제공하지 않는 알고리즘에서 효과적이다.
참고)
탐욕 알고리즘은 최적해를 구하는 데에 사용되는 근사적인 방법으로, 여러 경우 중 하나를 결정해야 할 때마다 그 순간에 최적이라고 생각되는 것을 선택해 나가는 방식으로 진행하여 최종적인 해답에 도달한다. 순간마다 하는 선택은 그 순간에 대해 지역적으로는 최적이지만, 그 선택들을 계속 수집하여 최종적(전역적)인 해답을 만들었다고 해서, 그것이 최적이라는 보장은 없다. 하지만 탐욕알고리즘을 적용할 수 있는 문제들은 지역적으로 최적이면서 전역적으로 최적인 문제들이다. -from wikipedia
탐욕적 알고리즘(greedy algorithm)은 조합 탐색(combinatiorial search) 문제의 각 단계에서 국부적으로 최적의 선택을 한다. 일반적으로 해당 문제에 대한 차선의 솔루션을 만든다. 하지만 완전 탐색 알고리즘(exhaustive search algorithm)은 모든 가능한 조합을 평가함으로 최적의 솔루션을 제공한다. 하지만, 실전에서 이를 사용하지 못하는 경우가 많고, 탐욕적 알고리즘이 덜 복잡하고 효율적으로 계산할 수 있는 솔루션을 제공해 준다.
순차 후진 선택(Sequential Backward Selection, SBS)
전통적인 순차 특성 선택 알고리즘이다. 계산 효율성을 향상시키기 위해 모델 성능을 가증한 적게 희생하면서,
초기 특성의 부분 공간으로 차원을 축소한다. (과대적합 문제를 SBS가 예측 성능을 높일 수 있다.)
SBS는 새로운 특성의 부분 공간이 목표 특성 개수가 될때까지 순차적으로 특성을 제거한다.
최대화할 기준 함수를 정하고, 이를 제거할 특성을 판단하는데 사용한다.
(기준함수에서 계산한 값은 특성을 제거하기 전후의 모델의 성능 차이이다. 각 단계에서 제거했을 떄 성능 손실이 최소가 되는
특성을 제거한다.)
1. 알고리즘을 k=d로 초기화 한다. d는 전체 특성 공간 Xd의 차원
2. 조건 x- = argmaxJ(Xk-x)를 최대화하는 특성 x=를 결정한다. x는 Xk의 부분
3. 특성 집합에서 특성 x-를 제거한다.
4. k가 목표 특성 개수가 되면 종료한다. 아니면 2단계로 돌아감
from sklearn.base import clone
from itertools import combinations
import numpy as np
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
class SBS():
def __init__(self, estimator, k_features, scoring=accuracy_score, test_size=0.25, random_state=1):
self.scoring=scoring
self.estimator=clone(estimator)
self.k_features=k_features
self.test_size=test_size
self.random_state=random_state
def fit(self, X, y):
X_train, X_test, y_train, y_test=\
train_test_split(X, y, test_size=self.test_size, random_state=self.random_state)
dim=X_train.shape[1]
self.indices_=tuple(range(dim))
self.subsets_=[self.indices_]
score=self._calc_score(X_train, y_train, X_test, y_test, self.indices_)
self.scores_=[score]
while dim>self.k_features:
scores=[]
subsets=[]
for p in combinations(self.indices_, r=dim-1):
score=self._calc_score(X_train, y_train, X_test, y_test, p)
scores.append(score)
subsets.append(p)
best=np.argmax(scores)
self.indices_=subsets[best]
self.subsets_.append(self.indices_)
dim-=1
self.scores_.append(scores[best])
self.k_score_=self.scores_[-1]
return self
def transform(self, X):
return X[:,self.indices_]
def _calc_score(self, X_train, y_train, X_test, y_test, indices):
self.estimator.fit(X_train[:,indices], y_train)
y_pred=self.estimator.predict(X_test[:, indices])
score=self.scoring(y_test, y_pred)
return score
목표 특성 개수를 지정하기 위해서 k_features 매개변수를 정의했다. sklearn의 accuracy_score 함수를 이용하여 모델 성능 평가
subsets은 검증 데이터셋(validation dataset)으로 이를 통해 훈련 데이터셋에서 원래 테스트 데이터셋을 미리 떼어 놓는다.
from sklearn.base import clone을 통해 추후에 모델 선택할 수 있다.
Scikit-learn의 KNN을 통한 구현
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=5)
sbs=SBS(knn, k_features=1)
sbs.fit(X_train_std, y_train)
k_feat=[len(k) for k in sbs.subsets_]
plt.plot(k_feat, sbs.scores_, marker='o')
plt.ylim([0.7, 1.02])
plt.ylabel('Accuracy')
plt.xlabel('Number of features')
plt.grid()
plt.tight_layout()
plt.show()
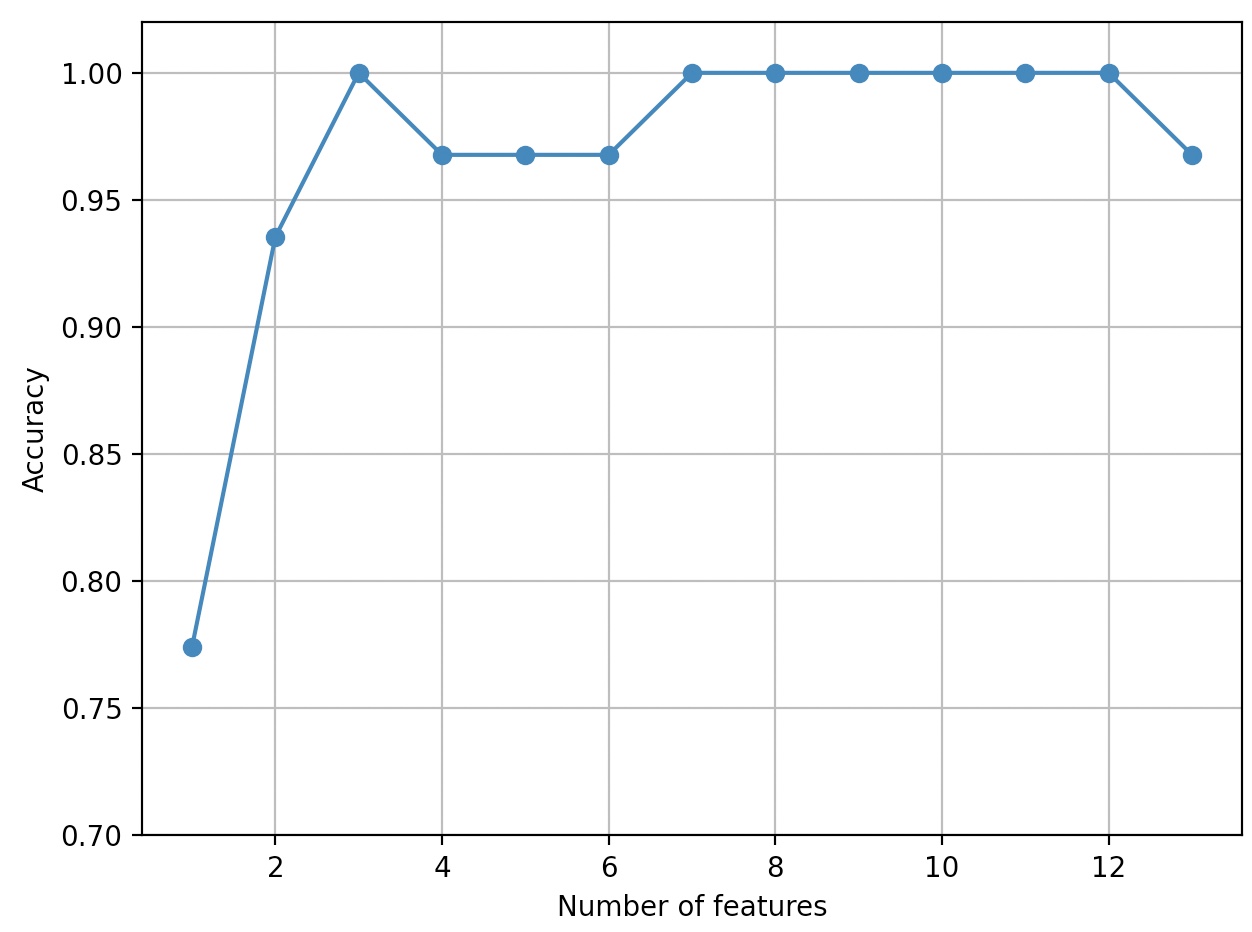
KNN분류기의 정확도가 특성개수가 줄어들면서 향상되었다.(k={3, 7, 8, 9, 10, 11, 12}에서 분류기가 100% 정확도를 달성)
차원의 저주가 감소함에 따라 정확도 증가
속성의 11번째 위치에 있는 세개의 특성에 대한 열 인덱스
k3=list(sbs.subsets_[10])
print(df_wine.columns[1:][k3])
Index(['Alchol', 'Malic acid', '0D280/0D315 of diluted wines'], dtype='object')
KNN 분류기의 성능
knn.fit(X_train_std, y_train)
print('훈련 정확도:', knn.score(X_train_std, y_train))
print('테스트 정확도:', knn.score(X_test_std, y_test))
훈련 정확도: 0.967741935483871
테스트 정확도: 0.9629629629629629
테스트 데이터에서도 준수한 성능을 보여준다.
3개의 특성에대한 KNN 성능
knn.fit(X_train_std[:,k3], y_train)
print('훈련 정확도:', knn.score(X_train_std[:,k3], y_train))
print('테스트 정확도:', knn.score(X_test_std[:,k3], y_test))
훈련 정확도: 0.9516129032258065
테스트 정확도: 0.9259259259259259
원본 특성의 4분의 1보다도 적은 특성을 사용했지만, 테스트 데이터셋의 예측 정확도가 감소했다.
위 세개의 특성에 담긴 판별 정보가 원래 데이터셋보다 적지 않다는 뜻이다.
( Wine 데이터셋은 작은 데이터셋임->무작위성에 매우 민감하다.
즉, 데이터셋을 훈련 데이터셋과 테스트 데이터셋으로 나눈 것과 훈련 데이터셋을 다시 훈련 서브셋과 검증 서브셋으로 나눈 방식에 영향을 받는다. )
특성 개수를 줄여서 KNN 모델 성능 자체가 증가하지는 않았지만, 데이터셋의 크기를 줄였다.
데이터 수집 비용이 높은 실전 애플리케이션에서는 유용하다. 또한 특성 개수가 줄었기에, 모델이 간단하고 해석하기 쉽다.
Scikit-learn 특성 선택 알고리즘
특성 가중치에 기반을 둔 재귀적 특성 제거(recursive feature elimination), 특성 중요도를 사용한 트리 기반 방법,
일변량 통계 테스트(univariate statistical test)가 있다.
Scikit-learn SequentialFeatureSelector
SequentialFeatureSelector의 첫번째 매개변수는 사용할 모델, n_features_to_select는 선택할 특성의 갯수
n_feature_to_select가 0-1사이이면 비율로 인식힌다.
direction 매개변수는 forward, backward로 방향을 지정할 수 있다. default값은 forward
cv 매개변수는 교차 검증 횟수를 지정한다. default값은 5이다.
(현재 남은 특성개수 m에 대하여 m X cv 개의 모델을 만든다.
from sklearn.feature_selection import SequentialFeatureSelector
scores=[]
for n_features in range(1, 13):
sfs=SequentialFeatureSelector(knn, n_features_to_select=n_features, n_jobs=-1)
sfs.fit(X_train_std, y_train)
f_mask=sfs.support_
knn.fit(X_train_std[:, f_mask], y_train)
scores.append(knn.score(X_train_std[:, f_mask], y_train))
plt.plot(range(1, 13), scores, marker='o')
plt.ylim([0.7, 1.02])
plt.ylabel('Accuracy')
plt.xlabel('Number of features')
plt.grid()
plt.tight_layout()
plt.show()
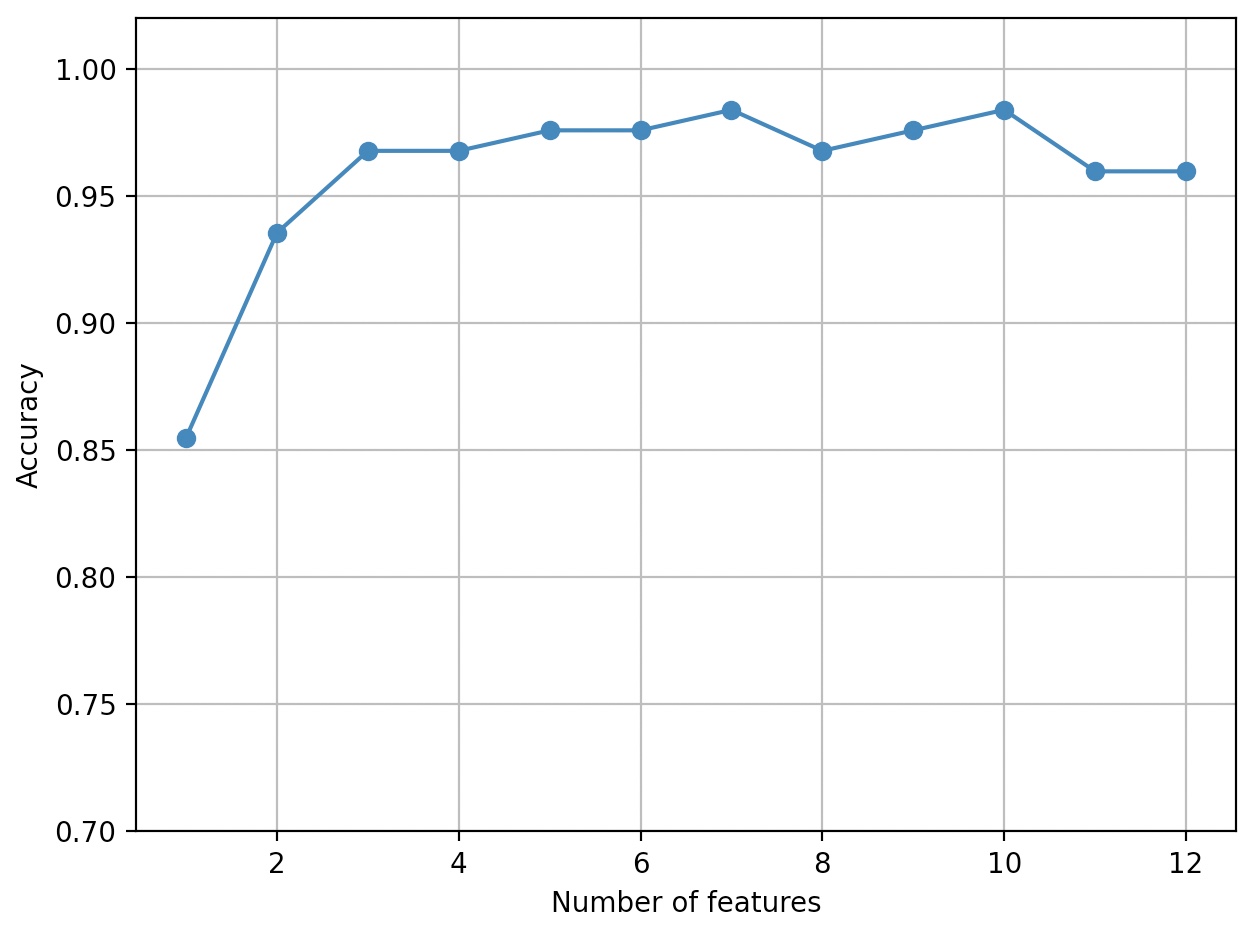
n_features_to_select=7, 10일 때 가장 높은 성능을 내고 있다.
가장 적은 특성을 선택한 것이 유리하다면 7개의 특성일 때가 가장 유리하다고 볼 수 있다.
n_features_to_elect=7 일 때의 순차 전지 선택 모델
sfs=SequentialFeatureSelector(knn, n_features_to_select=7, n_jobs=-1)
sfs.fit(X_train_std, y_train)
선택한 특성개수는 n_feature_to_select_ 에 저장되어 있다.
print(sfs.n_featue_to_select)
7
선택한 특성의 이름은 support_ 속성을 이용해서 얻을 수 있다.
f_mask=sfs.support_
df_wine.columns[1:][f_mask]
Index(['Alchol', 'Ash', 'Magnesium', 'Flavanoids', 'Color intensity', 'Hue',
'Proline'],
dtype='object')
knn.fit(X_train_std[:,f_mask], y_train)
print('훈련 정확도:',knn.score(X_train_std[:,f_mask],y_train))
print('테스트 정확도:',knn.score(X_test_std[:,f_mask],y_test))
훈련 정확도: 0.9838709677419355
테스트 정확도: 0.9814814814814815